日本語入力環境においては、変換するソフトウェアも重要だが、辞書も性能を大きく左右する要因である。Part5では、ユーザ辞書への単語の登録や削除などを行うためのツールについて解説する。
公式サイトはhttp://sumika.sourceforge.jp/である。
Sumika(栖)は、表雅仁氏により開発されている辞書管理ツールである。現在のところ、以下のような機能を持っている。
Dixchangeというのはここで初めて出てくる用語である。これはPRIMEの小松氏が中心となって始めた、日本語リソースの標準化を目的としたプロジェクトであり、Dixchange形式とはかな漢字変換エンジンの交換用辞書形式である。
また、Sumikaでまだ実現されていない具体的な目標としては以下の2つが挙げられている。
後者は特に、実現されればネット上で配布されているさまざまな辞書などを簡単にユーザ辞書に追加する事ができるようになって、随分とユーザーフレンドリーになるので、早期の実現が望まれる。と、紙面を借りて表氏にプレッシャーをかけておこう。
Sumikaの原稿執筆時点での最新版は0.10である。
Debianの場合は
#apt-get install sumika
でインストールは完了である。
Fedoraの場合はMandrakeのRPMを拝借してくるのがてっとり早いだろう。
$ sumika
でsumikaを起動するだけである。起動すると、Anthyの個人辞書の単語一覧画面が表示される。SKKの辞書編集やuimの設定がしたい場合は、メニューのオプションから切り替える。
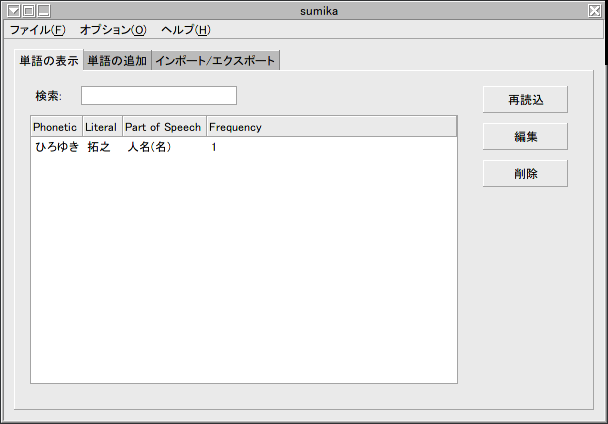
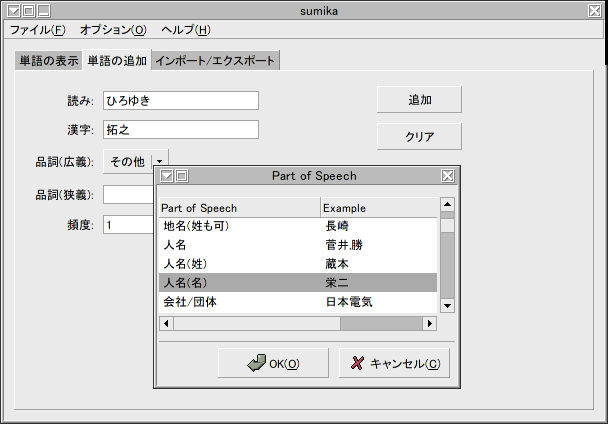
Anthyでは、1ユーザが持てる辞書は1つであるので、「どの個人辞書を編集するのか?」を選択する必要がない。Sumikaでは、Anthyの個人辞書に対して、登録単語の一覧の取得と編集、新規単語の登録、異なる辞書形式からのインポート、異なる辞書形式への個人辞書のエクスポートと、一通りの事が行える。使用に関して迷う事は少ないが、単語登録の際に狭義の品詞まで選択しないと登録できない事と、人名や地名を狭義の品詞として選択するためには、広義の品詞で名詞ではなく「その他」を選択しないといけない事に注意しよう。
SumikaによるAnthyの単語一覧画面
SumikaによるAnthyの単語登録画面
Sumikaは現時点ではATOKやMS-IMEの形式の辞書のインポートをできない。品詞のマッピングの問題があるのでSumikaがATOKやMS-IME形式の辞書をサポートするまでにはまだしばらく時間がかかるものと思われるが、ただ待っているだけというのも面白くない。そこで今回は一番需要がありそうな顔文字に関してのみCanna形式に変換するためのスクリプトをRubyで書いてみた。このスクリプトを使用すると、MS-IME形式の顔文字辞書をCanna形式に変換できる。(顔文字以外の品詞の単語に関しては単純に無視する。)
#!/usr/bin/ruby -Ke require 'kconv' while line = gets str = line.split(/\t/) next unless str[2] next unless str[2].toeuc.chop == "顔文字" print str[0].toeuc print " #KJ " puts str[1].toeuc.gsub(/ /, "\\ ") end
上記のコードをkao.rbという名前で保存すれば良い。保存時の文字エンコーディングはEUC-JPでなければならない事に注意。
kao.rbは標準入力からMS-IME形式の辞書を読みこんで、標準出力へCanna形式の辞書を出力する。下記の使用例では、jisyo.txtからMS-IME形式の辞書を読みこんで、jisyo.tへと書きだしている。
$ruby kao.rb < jisyo.txt > jisyo.t
これを使えばインターネット上に流通している大抵の顔文字辞書はCanna形式に変換できるはずだ。kao.rbでは単語に半角スペースが混ざっている場合の処理を行っているが、Sumikaで辞書をインポートする際、半角スペースが混じっているとうまくインポートできないというバグがあるようなので、気をつけていただきたい。このバグに関しては原稿を書き終えたあとに調査してパッチを送る予定にはしているが、あまり時間がないので修正が間に合うかどうかはわからない。
SKKの個人辞書の編集に関しては、原稿執筆時点ではとりあえず実装してみましたという程度のレベルであり、~/.skk-jisyoをEmacsなどのエディタで編集するのと大差ない。
SKKの辞書編集画面
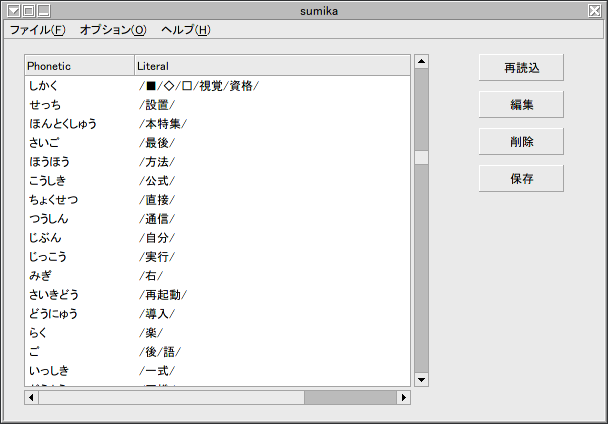
図上で編集したいものの上でクリックすると、編集が行える。
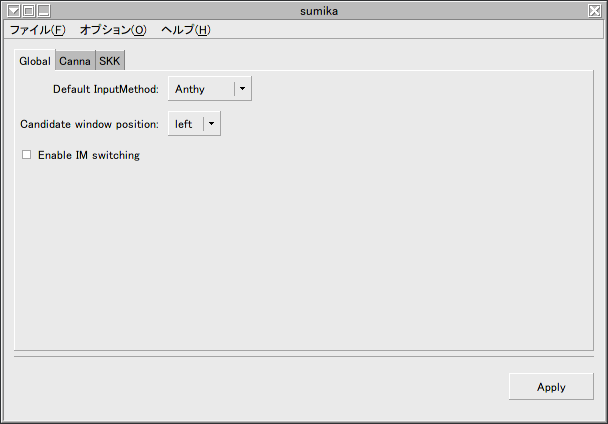
uimの設定に関しては特に語る事はないが、強いて書くならデフォルトのインプットメソッドを設定しても今はGTK_IM_MODULEやXMODIFIERSの設定の方が優先されてしまい、効果がない事ぐらいだろうか。
このスクリーンショットではメッセージが英語になっているが、この問題に関してはこの原稿を書いたあとに調査してパッチを送る予定である。うまくいけば、皆様のお手元に届く頃にはこの問題が修正された新しいバージョンが出ていると思う。
uimの設定画面
Sumikaという名称の由来は、松尾芭蕉の奥の細道の冒頭、「舟の上に生涯をうかべ馬の口とらへて老を迎ふる者は、日々旅にして旅を栖とす。」という文に由来するそうだ。辞書管理ツールと松尾芭蕉の接点は不明だが、そこらへんはあまり深く考えてはいけないものなのかもしれない。
公式サイトはhttp://linux-life.net/program/cc/kde/app/kannadic/である。
KannaDicはTasuku Suzuki氏により開発されているKDE用のかんな辞書エディタだ。もちろん、GNOMEを使っている環境でも動作する。原稿執筆時点での最新版は1.7.0である。
KannaDicでできる事は以下の通りである。
いろいろな機能があるように見えて、結局は全部Cannaの辞書を管理するための機能だ。目的がハッキリしているので使いやすい。
Debianの場合はkmuto氏により、KannadicのDebパッケージが提供されている。
deb http://www.topstudio.co.jp/~kmuto/debian/private unstable main
を/etc/apt/sources.listに追加して、
# apt-get install kannadic
を実行すれば、インストールは完了だ。
Fedoraの場合はソースコードからビルドする事になる。ビルドにはかなり多くのパッケージが必要になる。以下のようなRPMパッケージをインストールしておく必要がある。
#yum install kdelibs-devel zlib-devel XFree86-devel
筆者は闇雲にyumでパッケージをインストールしてしまったので、他にも必要なRPMがあるかもしれない。
KannaDicの典型的な使用法は、
1.ユーザ辞書を開く
2.ユーザ辞書に対し、単語登録 or 辞書編集 or 辞書のインポート・エクスポートを行う
3.保存する
となる。要するに、辞書を開いて編集してから保存するという、当たり前の話である。最初の一回はこれにユーザ辞書を開く前にユーザ辞書を作るという作業が加わる。
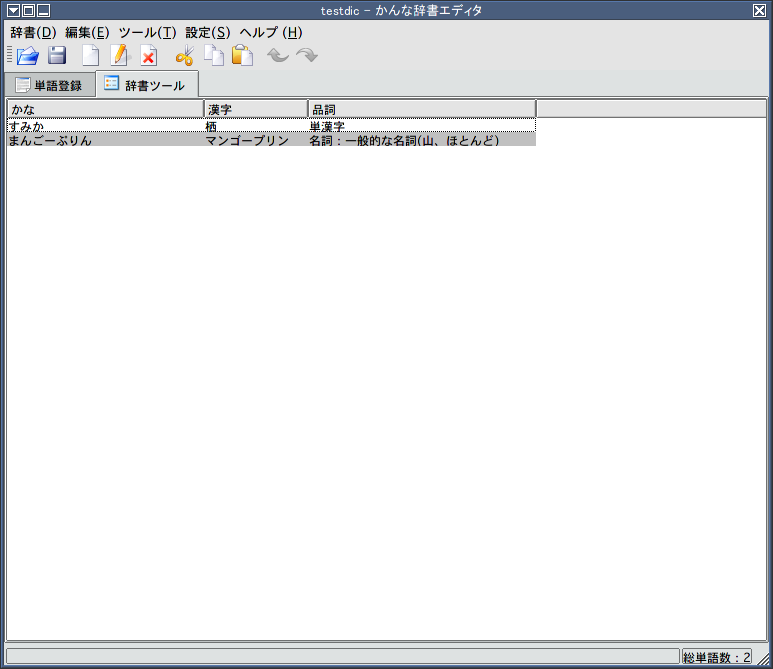
使い方に関しては特に問題はないだろう。単語選択と辞書の編集の画面はわかれており、それぞれ「単語登録」「辞書ツール」のタブで切り替えられる。
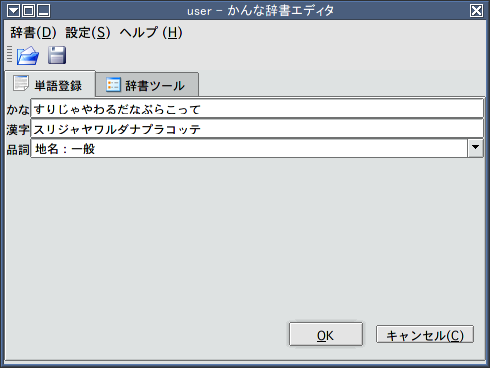
単語登録を行う際には、まず「単語登録」タブに切りかえる。よみと単語(画面では漢字となっているが、もちろん漢字以外も登録できる)を入力して、品詞を選択してからOKを押すだけである。ここでキャンセルを押すとKannaDic自体が終了するので、少し気をつけよう。
辞書の編集に関しては、「辞書ツール」タブに切り替えてから、編集したい単語の上でクリックすると編集用の小さなウィンドウがでてくるので、そこで編集する。
各種辞書のインポート・エクスポートは、「辞書ツール」タブに切り替えて、メニューの「ツール」から「インポート」もしくは「エクスポート」を選んで、インポート元の辞書もしくはエクスポート先の辞書ファイルを選択する。
KannaDicでは新しいユーザ辞書を作成する事も可能であるが、ユーザ辞書を作成した場合は、それを使うために設定をしておかないといけない事に注意しよう。
KannaDicの辞書編集画面
KannaDicの単語一覧画面
SKK Openlabでは、SKKの辞書整理用のツールも配布している。skkdic-expr、skkdic-sort、skkdic-expr2、skkdic-countの4つのツールが1セットになって配布されているが、skkdic-expr2を使えばskkdic-exprとskkdic-sortは必要ないので、今回はskkdic-expr2とskkdic-countについて解説する。
Debianの場合は
# apt-get install skktools
でインストールは終了する。
Fedoraの場合はRPMは用意されていないので、http://openlab.ring.gr.jp/skk/tools/からソースコードをダウンロードしてきて自力でビルドする事になる。インストール手順は以下の通り。
$ cd ダウンロードしてきたディレクトリ $ tar xvjf skktools-1.1.tar.bz2 $ cd skktools-1.1 $ ./configure $ make # make installskkdic-expr2
skkdic-expr2は複数のSKK辞書を結合したり、他の辞書との差分をとるのに使用する。例えば、JISYO1とJISYO2を結合してJISYO3に出力するには、
$ skkdic-expr2 JISYO1 + JISYO2 > JISYO3
とすれば良い。逆に差分を取る場合には、
$ skkdic-expr2 JISYO1 - JISYO2 > JISYO3
となる。3つ以上の辞書を同時に扱う事もできる。例えば、JISYO1と JISYO2を結合して、JISYO3の内容を削除した辞書をJISYO4に書きだすためには、以下のようにすれば良い。
$ skkdic-expr2 JISYO1 + JISYO2 - JISYO3 > JISYO4
skkdic-expr2の出力はSKK辞書のフォーマットに従っているので、そのままSKK辞書として使用する事ができる。
skkdic-countはSKK辞書に含まれる候補数を数えるためのツールである。使い方は以下のとおり。
$skkdic-count JISYO
例えば、L辞書をskkdic-countにかけると、
$skkdic-count /usr/share/skk/SKK-JISYO.L /usr/share/skk/SKK-JISYO: 156471 candidates
となり、候補数は15万6471個である事がわかる。
GUIで使える辞書ツールの数はあまり多くない。今回は比較的新しいGUI辞書ツールを2つ紹介してみた。Anthyの辞書を編集したいならSumika、Cannaの辞書を編集したいならKannaDicという事になる。GUI辞書ツールよりもSKK方式で入力できるXIMサーバの方が多いというこの状況は、良くも悪くも現在のUnixの状況を表していると言えるのではないだろうか。