今日では、日本語をコンピュータで入力する際には、一般にかな漢字変換と呼ばれる方式が用いられている。Part1ではかな漢字変換方式についての解説と、かな漢字変換を実現するための仕組みについての解説を行う。
漢字かな交じりの日本語の文章をキーボードから直接入力する事は難しい。(T-Code方式やTUT-Code方式のように、直接入力する方式も存在するが、これらについてはここでは触れない。)そこで、かなを入力してから漢字へと変換する事で漢字交じり文を入力うる、という2段階の手順を踏むのが一般的であり、この方式はかな漢字変換方式と呼ばれる。
キーボードからかなを入力するための方法には、メジャーなものが2つある。ひとつがローマ字入力方式で、もうひとつがかな入力方式である。ローマ字入力方式は子音と母音を組みあわせて、アルファベットからかなを生成する方式であり、これがもっともよく使われる方式である。かな入力方式は、キーボードから直接かなを入力する方式である。ただし、かな入力方式の場合でも、濁音や半濁音に関しては複数回のタイプでひとつの文字を入力する。
他にも、ローマ字入力方式の拡張であるAZIK方式や、親指シフト方式など、かなを入力するためにはいくつかの方式が存在する。
かなを入力したあとは、必要に応じて漢字に変換しなければならない。かなを漢字に変換するための方式としては、単語変換方式や単文節変換方式、連文節変換方式などの分類がある。
単語変換は「わたし」を「私」に変換するというような、1つの単語のみを変換する方式である。単文節変換は「わたしは」を「私は」に変換するような、1つの文節を変換する方式である。連文節変換は、「わたしのなまえはなかのです」を「私の名前は中野です」と変換するような、複数の文節を一度に変換する方式である。もちろん、この中で一番良く使われるのは連文節変換方式である。
世界には、文字数が多すぎてキーボードから直接入力できない言語がいくつかある。もちろん、日本語もその中のひとつだ。そのような言語を入力するためのソフトウェアをインプットメソッドと呼ぶ。
さて、インプットメソッドはアプリケーションとは別のプログラムとして実装されているわけだが、では両者の間はどのような情報をやりとりしているのだろうか?
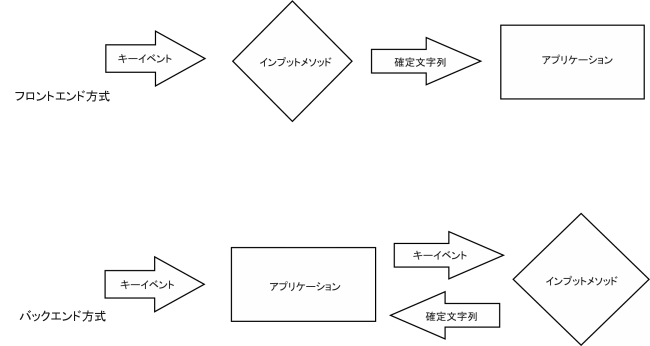
キーをタイプするすると、キーが押された事を知らせるためのキーイベントが発生する。発生したキーイベントがまずインプットメソッドに送られるか、それとも現在アクティブなアプリケーションへと送られるかで、インプットメソッドには2種類の形態が存在する。前者の場合のインプットメソッドをフロントエンド方式、後者の場合をバックエンド方式という。昔はFEP(FEPの名称の由来と本来の意味についてはコラム1を参照。)などフロントエンド方式のインプットメソッドが多かったが、最近はバックエンド方式が多い。
フロントエンド方式の場合はキーイベントはインプットメソッドが受けとり、アプリケーションに対しては変換が終わった文字列を送りつける。もちろん、インプットメソッドで必要としない場合にはキーイベントをアプリケーションに素通しする事もある。フロントエンド方式は単純であるが、アプリケーションと連携しない事が多いために使い勝手があまりよくない場合がある。
バックエンド方式の場合は、キーイベントを受けとったアプリケーションは、そこからさらにインプットメソッドに対してキーイベントを送りつける。インプットメソッドはそのキーイベントと現在の状態から現在の未確定文字列と確定文字列を計算し、アプリケーション側へと返す。未確定文字列はインプットメソッド側で描画する場合もあるが、その場合にはどこに描画するのかという情報をアプリケーションからインプットメソッドへと渡さなければインライン入力(キャレットのある位置に未確定文字列を表示する事)ができない。
アプリケーションは受けとった未確定文字列をしかるべき位置(大抵はキャレットのある場所である)に表示し、確定文字列はキャレットのある位置に挿入されたものとして扱う。
実用的なシステムを作ろうとすると、どうしてもアプリケーションとインプットメソッドの間でキャレットの座標やキャレットの近くにあるテキストなど、ある程度の情報のやりとりが必要になる(=アプリケーション側で対応が必要になる)のはフロントエンド方式でもバックエンド方式でも同じであるので、2つの方式の違いはそう大きなものでもないと思うのだが、時代の流れはフロントエンド方式をアプリケーションと協調動作させる方向には行かず、バックエンド方式に流れてしまった。
インプットメソッドという言葉はキーボードから直接入力できない文字を入力するためのソフトウェア、といった程度の意味合いで、変換エンジンもインプットメソッドの範疇に入るし、kinput2などのようにアプリケーションと変換エンジンの間に入ってやりとりを行うソフトウェアもインプットメソッドに入る。というか、ネット上での議論を見ていると、あまり深く考えて区別していない人が多いように思われる。
このkinput2のようにアプリケーションと変換エンジンの間に入る部分のソフトウェアのみを呼ぶための言葉がないので、この特集では以後インプットメソッドという言葉を、kinput2などアプリケーションと直接やりとりするソフトウェアのみに限定して使い、変換エンジンとは区別する事にする。
フロントエンド方式とバックエンド方式
Unixにおける日本語入力システムの状況は複雑である。魔界であると言っても過言ではない。まずはX Window System上の話をしよう。
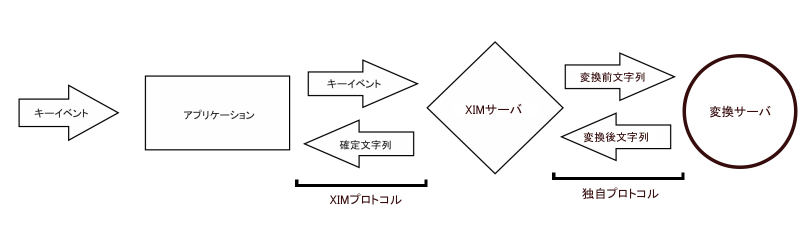
X Window SystemにはXIM(X Input Method)という、インプットメソッドのための仕組みが用意されている。XIMはサーバ・クライアント型の仕組みであり、インプットメソッドはXIMサーバ、アプリケーションはXIMクライアントと呼ばれる。XIMクライアントという言葉はあまり使わないが、XIMサーバという言葉はよく使われるので、覚えておいても損ではない。XIMサーバとXIMクライアントの間はXIMプロトコルと呼ばれるプロトコルで通信する。
アプリケーションはキーイベントをXIMサーバに送り、XIMサーバは受けとったキーイベントで変換を行い、確定文字列などを返す。アプリケーション側から見える話はここまでである。
実際には、日本語入力を行う場合、多くのXIMサーバはさらに別プロセスの変換エンジンと独自のプロトコルで通信して変換を行っている。言い換えると、XIMサーバは実際の変換処理をさらに変換エンジンへと丸投げしている。これは、初期に普及した変換エンジンであるWnnやCannaがマルチユーザ・サーバとして実装されており、これらを利用するためにはXIMサーバをWnnやCannaのクライアントとするのが自然だったためであるものと思われる。というか、これ以外に自然な実装方法はちょっと思いつけそうにない。
XIMサーバがWnnやCannaのクライアントになる、という文章で読者の方が混乱してしまいそうな事はよくわかっているのだが、他に表現方法がないので、混乱した人には図を見ながらよく考えてみて欲しい。
多くのXIMサーバは、とは書いたが、このような独自プロトコルでの通信を行っていないXIMサーバもある。skkinputやuim-ximがその例である。
なお、XIMの仕組みに関しては、井上氏のサイト(http://home.catv.ne.jp/pp/ginoue/im/)に詳しい解説がある。興味を持った方はこちらも読まれると良い。
典型的なXIMを使用した場合
コラムにも書いたが、Gtk+とQtという2大GUIライブラリには、immoduleという仕組みが実装されている。(Gtk+は2.0から実装されている。QtはQt3用のパッチが公開され、Qt4に取りこんでもらえるように現在交渉中。)この両者のimmoduleは名前が同じだけで、モジュールの仕様には互換性はない。そもそも両immoduleとも、Gtk+やQtにべったりと依存しているので、互換性など取れるわけがない。だから、変換用モジュールの互換性は、同じくコラムに出てきたuimやIIIMFのレイヤで実装される事になる。
なぜこんな複雑になってしまったかというと、XIMが広まりすぎてしまったせいである。そして代替となる仕組みが長くでてこなかったために、このような混乱が起こってしまった。3年後ぐらいには多少はマシな状態になっているだろうが、混乱が収束するにはまだしばらくの時間が必要である。
immoduleのXIMに対する利点はいくつかある。まず、動的に入力言語の切り換えが可能である事が挙げられる。XIMでも動的な入力言語の切り替えは不可能ではないのだが、事実上は不可能であった。XIMでは入力言語を切り替えるための手段としてはXIMサーバ自体を動的に切り替えるか、XIMサーバ内部で言語を切り替えるかの2つが考えられるが、前者の実装であるximswitchはxlibにパッチを当てる必要があったため普及しなかった。後者は、XIMプロトコルがCompoundTextというエンコーディングで文字列をやりとりするのだが、xlibには現在のロケールで使用するエンコーディングからCompoundTextにエンコードするためのAPIしか用意されていなかったため、入力言語の切り替えのために動的にsetlocaleが必要になるという事で、実装しているXIMサーバが存在しない。
次に、immoduleには、XIMに欠けているキャレットの座標を取得する方法が用意されている。XIMはroot window style, off the spot style, on the spot style, over the spot styleと、プリエディット(未確定文字列)を描画するための方法を4つ用意している(それぞれのスタイルに関してはコラム2を参照)が、そのうちキャレットの座標を取得できるのはover the spot styleの場合だけである。これに関してはXIMの仕様策定の時に、「パフォーマンスが落ちるから」という理由で、どうしてもキャレット座標の必要なover the spot style以外ではキャレットの座標が送られないようにされてしまったそうである。なんとも悲しい話というか、日本人からしてみれば、無茶苦茶な話である。つい最近、openi18n-imというMLにover the spot以外のstyleでもキャレットの座標を送信するようにするパッチが出されたが、さすがに今となっては遅すぎる感が否めない。これに対し、immoduleではキャレットの座標を取得するための(正確にはキャレットの座標をセットするための)APIが用意されている。もっとも、このAPIを使ってくれないアプリケーション(Mozillaとか)があるので、結局苦労がなくなるわけではないのだが。オープンソースコミュニティには国際化に対する興味や知識のない開発者も多く、マルチバイト圏の人間の苦労はなかなか絶えない。
immoduleの概略
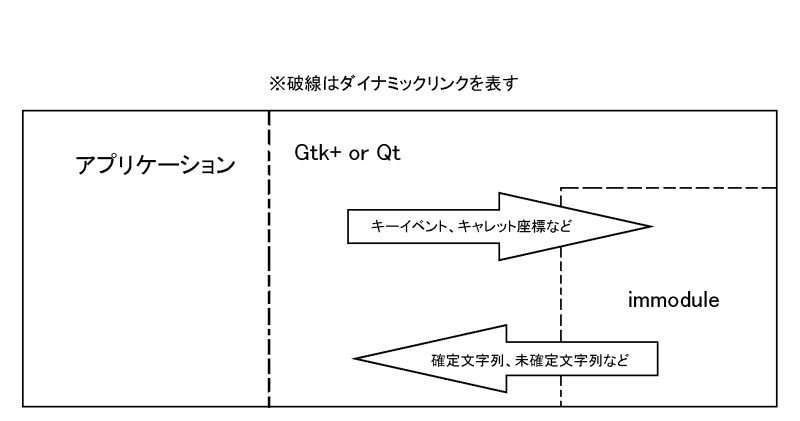
図のimmoduleは、日本語入力を実際にはそこからさらに変換エンジン用のライブラリとダイナミックリンクしていたり、変換サーバと通信したりする場合が多いので、immoduleになったからといって魔法のようにシンプルな仕組みになるわけではない。
コンソールで日本語入力を行うための方式は、現在のところ大別して二種類存在する。1つはキー入力をアプリケーションよりも先に処理するFEPであり、もう1つは個々のアプリケーションに日本語入力用のソフトウェアを組みこんでしまったものである。コンソールで広く使われているインプットメソッド用のライブラリ/フレームワークは現在のところ存在しない。
日本語入力プログラムの歴史に関するコラムは、リンク先でお楽しみ下さい。実はこのコラムを書くのはかなり大変で、三日もかかってたりします。その割に本では中身が削られてりしてたけど。
XIMのプリエディット描画スタイルに関するコラムは、リンク先でお楽しみ下さい。このコラムを書くのはあんまり大変じゃなかった。
たいした事書いてなかったので削除。というか、ここに限らず、編集さんが書き足してるところってけっこうあります。